library(tidyverse)
library(janitor)
library(knitr)
library(kableExtra)12 Binding and joining
12.1 Dependencies
12.2 Simluate data
12.3 Practice pivoting and summarizing
- Create a data frame that contains the id, gender and age data.
- No pivot needed.
- Create a separate data frame with the id and sum scores with each participants’ scores on each depression scale.
- Convert the wide data to long.
- Calculate a mean score for each participant and each of the scales.
- Covert the data back to wider so that it’s one row per participant.
NoteClick to show answer
dat_demographics <- dat_likert_wide %>%
# select rows of interest
select(id, age, gender)
dat_likert_scored <- dat_likert_wide %>%
# pivot longer
pivot_longer(cols = starts_with("depression"),
names_to = "scale_item",
values_to = "response") %>%
# separate scale_item into scale and item
separate(scale_item, into = c("scale", "item"), sep = "_") %>%
# calculate sum scores for each participant and scale
group_by(id, scale) %>%
summarize(mean_score = mean(response)) %>%
ungroup() %>%
# pivot wider
pivot_wider(names_from = "scale",
values_from = "mean_score")
NoteClick to show answer
# alternative solution
dat_demographics <- dat_likert_wide %>%
# select rows of interest
select(id, age, gender)
dat_likert_scored <- dat_likert_wide %>%
# pivot longer
pivot_longer(cols = starts_with("depression"),
names_to = c("scale", "item"),
names_sep = "_",
values_to = "response") %>%
# calculate sum scores for each participant and scale
summarize(mean_score = mean(response),
.by = c("id", "scale")) %>%
# pivot wider
pivot_wider(names_from = "scale",
values_from = "mean_score") 12.4 Combining datasets
12.4.1 Why cbind()/bind_cols() and rbind()/bind_rows() should be avoided
cbind()/rbind(): Base Rbind_cols()/bind_rows(): tidyverse, but still not preferred.
From the bind_cols() documentation: “Where possible prefer using a join to combine multiple data frames. bind_cols() binds the rows in order in which they appear so it is easy to create meaningless results without realising it.”
12.4.1.1 Row mismatches
# shuffle the rows
set.seed(42)
dat_demographics_shuffled <- dat_demographics %>%
# randomise rows to make combination more difficult
sample_frac(size = 1, replace = FALSE)
dat_likert_scored_shuffled <- dat_likert_scored %>%
# randomise rows to make combination more difficult
sample_frac(size = 1, replace = FALSE)
# bind columns
dat_combined_cbind <- cbind(dat_demographics_shuffled,
dat_likert_scored_shuffled)
dat_combined_bind_cols <- bind_cols(dat_demographics_shuffled,
dat_likert_scored_shuffled)
head(dat_combined_bind_cols, n = 8)| id…1 | age | gender | id…4 | depression1 | depression2 |
|---|---|---|---|---|---|
| 1 | 20 | female | 8 | 3.2 | 5.142857 |
| 5 | 28 | male | 7 | 3.7 | 3.857143 |
| 8 | 29 | female | 4 | 4.1 | 3.142857 |
| 6 | 32 | male | 1 | 4.4 | 3.714286 |
| 2 | 39 | female | 5 | 4.9 | 4.571429 |
| 4 | 36 | female | 2 | 5.8 | 4.285714 |
| 3 | 30 | male | 3 | 3.6 | 5.142857 |
| 7 | 40 | female | 6 | 3.8 | 4.571429 |
Why is this dangerous?
12.4.1.2 Invisible row mismatches
Without unique IDs, its not even obvious anything has gone wrong.
dat_demographics_shuffled2 <- dat_demographics_shuffled %>%
select(-id)
dat_likert_scored_shuffled2 <- dat_likert_scored_shuffled %>%
select(-id)
dat_combined_bind_cols2 <- bind_cols(dat_demographics_shuffled2,
dat_likert_scored_shuffled2)
head(dat_combined_bind_cols2, n = 8)| age | gender | depression1 | depression2 |
|---|---|---|---|
| 20 | female | 3.2 | 5.142857 |
| 28 | male | 3.7 | 3.857143 |
| 29 | female | 4.1 | 3.142857 |
| 32 | male | 4.4 | 3.714286 |
| 39 | female | 4.9 | 4.571429 |
| 36 | female | 5.8 | 4.285714 |
| 30 | male | 3.6 | 5.142857 |
| 40 | female | 3.8 | 4.571429 |
12.4.1.3 More severe row mismatches throw errors
# shuffle the rows and add duplicates or missingness
set.seed(42)
dat_demographics_shuffled_missing <- dat_demographics %>%
# add errors in the form of missing data, plus randomise rows
sample_frac(size = 0.75, replace = FALSE)
dat_likert_scored_shuffled_duplicates <- dat_likert_scored %>%
# add errors in the form of duplicates
dirt_duplicates(prop = 0.25) %>%
# randomise rows to make combination more difficult
sample_frac(size = 1, replace = FALSE)dat_demographics_shuffled_missing %>%
count()| n |
|---|
| 6 |
dat_likert_scored_shuffled_duplicates %>%
count()| n |
|---|
| 10 |
dat_demographics_shuffled_missing %>%
as_tibble() %>%
select(id) %>%
head(n = 10)| id |
|---|
| 1 |
| 5 |
| 8 |
| 6 |
| 2 |
| 4 |
dat_likert_scored_shuffled_duplicates %>%
select(id) %>%
head(n = 10)| id |
|---|
| 6 |
| 5 |
| 2 |
| 1 |
| 3 |
| 8 |
| 1 |
| 4 |
| 7 |
| 2 |
dat_combined_cbind <- cbind(dat_demographics_shuffled_missing,
dat_likert_scored_shuffled_duplicates)
dat_combined_bind_cols <- bind_cols(dat_demographics_shuffled_missing,
dat_likert_scored_shuffled_duplicates)12.5 Joins
Intelligently join two data frames together using one or more reference columns.
12.5.1 Mutating joins
12.5.1.1 full_join()
All rows and all columns from both x and y. Where there are not matching values, returns NA for the one missing.
knitr::include_graphics("../images/join_full.gif")
dat_full_join <- full_join(x = dat_demographics_shuffled_missing,
y = dat_likert_scored_shuffled_duplicates,
by = "id")
dat_demographics_shuffled_missing %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
dat_likert_scored_shuffled_duplicates %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 1 | 4.4 | 3.714286 |
| 1 | 4.4 | 3.714286 |
| 2 | 5.8 | 4.285714 |
| 2 | 5.8 | 4.285714 |
| 3 | 3.6 | 5.142857 |
| 4 | 4.1 | 3.142857 |
| 5 | 4.9 | 4.571429 |
| 6 | 3.8 | 4.571429 |
| 7 | 3.7 | 3.857143 |
| 8 | 3.2 | 5.142857 |
dat_full_join %>%
head(n = 10) %>%
arrange(id)| id | age | gender | depression1 | depression2 |
|---|---|---|---|---|
| 1 | 20 | female | 4.4 | 3.714286 |
| 1 | 20 | female | 4.4 | 3.714286 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 3 | NA | NA | 3.6 | 5.142857 |
| 4 | 36 | female | 4.1 | 3.142857 |
| 5 | 28 | male | 4.9 | 4.571429 |
| 6 | 32 | male | 3.8 | 4.571429 |
| 7 | NA | NA | 3.7 | 3.857143 |
| 8 | 29 | female | 3.2 | 5.142857 |
What is participant 5’s age and depression1 score? Are they correct in the joined dataset?
What issues still remain?
12.5.1.2 left_join()
All rows from x, and all columns from x and y. Rows in x with no match in y will have NA values in the new columns.
knitr::include_graphics("../images/join_left.gif")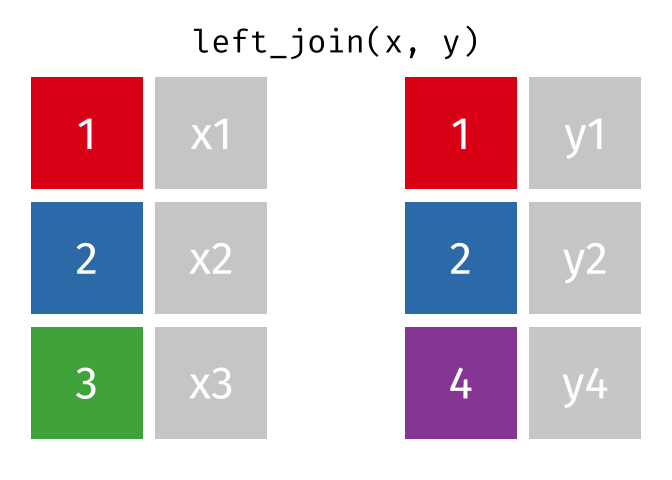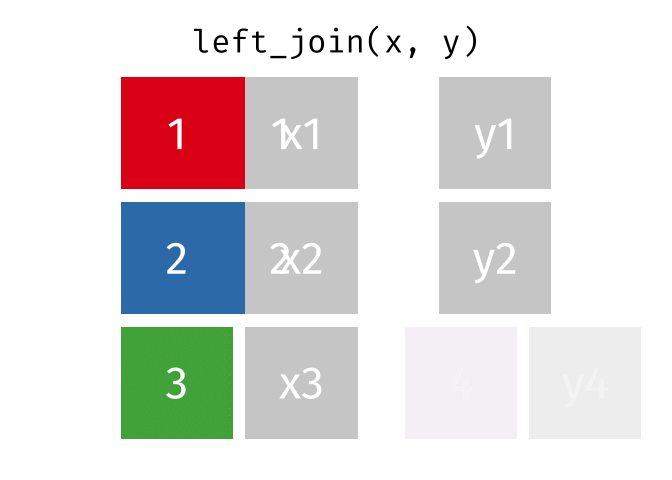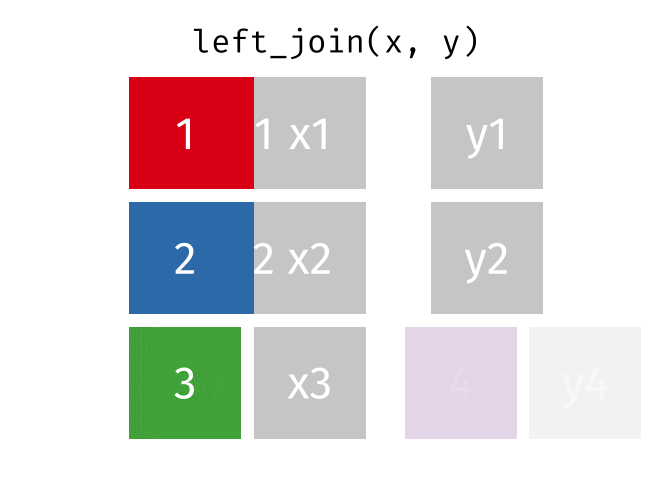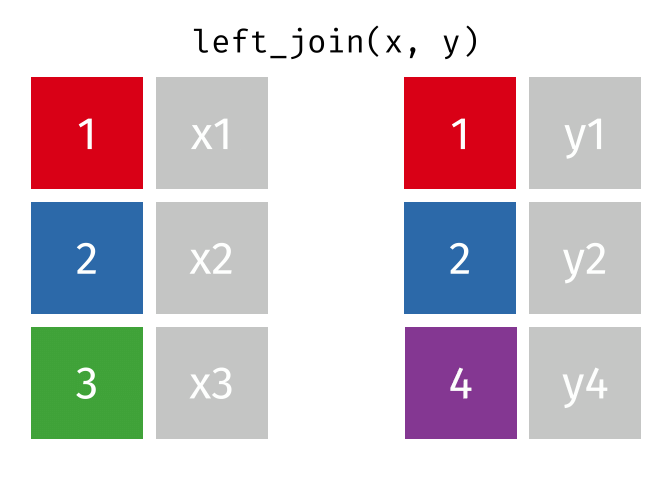
knitr::include_graphics("../images/join_left_extra_y.gif")
dat_full_left <- left_join(x = dat_demographics_shuffled_missing,
y = dat_likert_scored_shuffled_duplicates,
by = "id")
dat_demographics_shuffled_missing %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
dat_likert_scored_shuffled_duplicates %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 1 | 4.4 | 3.714286 |
| 1 | 4.4 | 3.714286 |
| 2 | 5.8 | 4.285714 |
| 2 | 5.8 | 4.285714 |
| 3 | 3.6 | 5.142857 |
| 4 | 4.1 | 3.142857 |
| 5 | 4.9 | 4.571429 |
| 6 | 3.8 | 4.571429 |
| 7 | 3.7 | 3.857143 |
| 8 | 3.2 | 5.142857 |
dat_full_left %>%
head(n = 10) %>%
arrange(id)| id | age | gender | depression1 | depression2 |
|---|---|---|---|---|
| 1 | 20 | female | 4.4 | 3.714286 |
| 1 | 20 | female | 4.4 | 3.714286 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 4 | 36 | female | 4.1 | 3.142857 |
| 5 | 28 | male | 4.9 | 4.571429 |
| 6 | 32 | male | 3.8 | 4.571429 |
| 8 | 29 | female | 3.2 | 5.142857 |
12.5.1.3 right_join()
All rows from y, and all columns from x and y. Rows in y with no match in x will have NA values in the new columns.
knitr::include_graphics("../images/join_right.gif")
dat_full_right <- right_join(x = dat_demographics_shuffled_missing,
y = dat_likert_scored_shuffled_duplicates,
by = "id")
dat_demographics_shuffled_missing %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
dat_likert_scored_shuffled_duplicates %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 1 | 4.4 | 3.714286 |
| 1 | 4.4 | 3.714286 |
| 2 | 5.8 | 4.285714 |
| 2 | 5.8 | 4.285714 |
| 3 | 3.6 | 5.142857 |
| 4 | 4.1 | 3.142857 |
| 5 | 4.9 | 4.571429 |
| 6 | 3.8 | 4.571429 |
| 7 | 3.7 | 3.857143 |
| 8 | 3.2 | 5.142857 |
dat_full_right %>%
head(n = 10) %>%
arrange(id)| id | age | gender | depression1 | depression2 |
|---|---|---|---|---|
| 1 | 20 | female | 4.4 | 3.714286 |
| 1 | 20 | female | 4.4 | 3.714286 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 3 | NA | NA | 3.6 | 5.142857 |
| 4 | 36 | female | 4.1 | 3.142857 |
| 5 | 28 | male | 4.9 | 4.571429 |
| 6 | 32 | male | 3.8 | 4.571429 |
| 7 | NA | NA | 3.7 | 3.857143 |
| 8 | 29 | female | 3.2 | 5.142857 |
12.5.1.4 inner_join()
All rows from x where there are matching values in y, and all columns from x and y.
Note that an inner join is both left and right.
knitr::include_graphics("../images/join_inner.gif")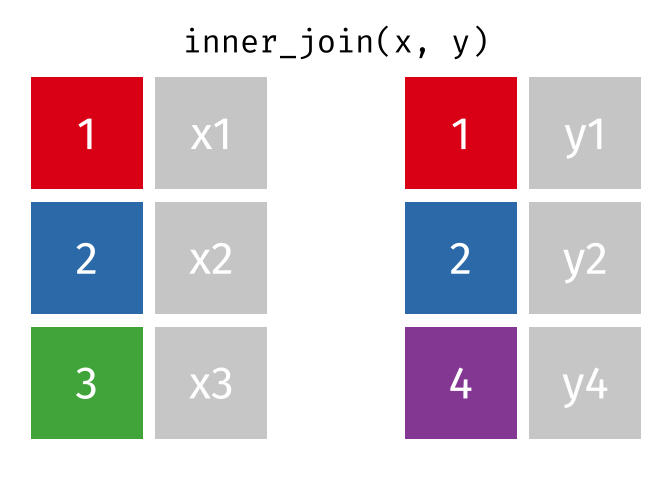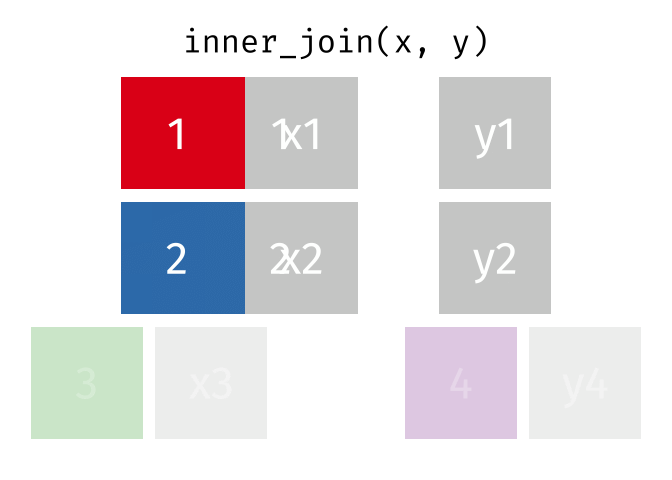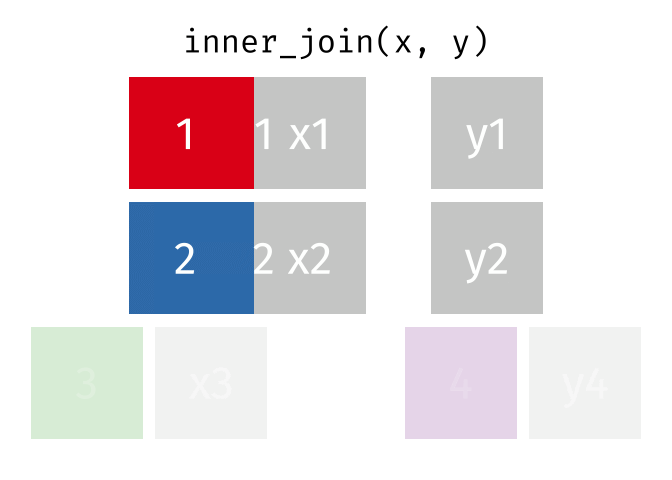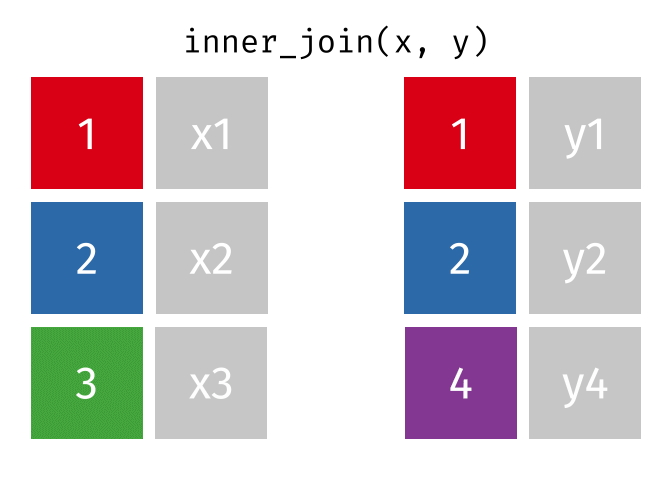
dat_full_inner <- inner_join(x = dat_demographics_shuffled_missing,
y = dat_likert_scored_shuffled_duplicates,
by = "id")
dat_demographics_shuffled_missing %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
dat_likert_scored_shuffled_duplicates %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 1 | 4.4 | 3.714286 |
| 1 | 4.4 | 3.714286 |
| 2 | 5.8 | 4.285714 |
| 2 | 5.8 | 4.285714 |
| 3 | 3.6 | 5.142857 |
| 4 | 4.1 | 3.142857 |
| 5 | 4.9 | 4.571429 |
| 6 | 3.8 | 4.571429 |
| 7 | 3.7 | 3.857143 |
| 8 | 3.2 | 5.142857 |
dat_full_inner %>%
head(n = 10) %>%
arrange(id)| id | age | gender | depression1 | depression2 |
|---|---|---|---|---|
| 1 | 20 | female | 4.4 | 3.714286 |
| 1 | 20 | female | 4.4 | 3.714286 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 2 | 39 | female | 5.8 | 4.285714 |
| 4 | 36 | female | 4.1 | 3.142857 |
| 5 | 28 | male | 4.9 | 4.571429 |
| 6 | 32 | male | 3.8 | 4.571429 |
| 8 | 29 | female | 3.2 | 5.142857 |
12.5.2 Filtering joins
12.5.2.1 semi_join()
All rows from x where there are matching values in y, keeping just columns from x.
knitr::include_graphics("../images/join_semi.gif")
dat_semi <- semi_join(x = dat_demographics_shuffled_missing,
y = dat_likert_scored_shuffled_duplicates,
by = "id")
dat_demographics_shuffled_missing %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
dat_likert_scored_shuffled_duplicates %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 1 | 4.4 | 3.714286 |
| 1 | 4.4 | 3.714286 |
| 2 | 5.8 | 4.285714 |
| 2 | 5.8 | 4.285714 |
| 3 | 3.6 | 5.142857 |
| 4 | 4.1 | 3.142857 |
| 5 | 4.9 | 4.571429 |
| 6 | 3.8 | 4.571429 |
| 7 | 3.7 | 3.857143 |
| 8 | 3.2 | 5.142857 |
dat_semi %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
12.5.2.2 anti_join()
All rows from x where there are not matching values in y, keeping just columns from x.
knitr::include_graphics("../images/join_anti.gif")
dat_full_anti <- anti_join(x = dat_likert_scored_shuffled_duplicates,
y = dat_demographics_shuffled_missing,
by = "id")
dat_demographics_shuffled_missing %>%
head(n = 10) %>%
arrange(id)| id | age | gender |
|---|---|---|
| 1 | 20 | female |
| 2 | 39 | female |
| 4 | 36 | female |
| 5 | 28 | male |
| 6 | 32 | male |
| 8 | 29 | female |
dat_likert_scored_shuffled_duplicates %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 1 | 4.4 | 3.714286 |
| 1 | 4.4 | 3.714286 |
| 2 | 5.8 | 4.285714 |
| 2 | 5.8 | 4.285714 |
| 3 | 3.6 | 5.142857 |
| 4 | 4.1 | 3.142857 |
| 5 | 4.9 | 4.571429 |
| 6 | 3.8 | 4.571429 |
| 7 | 3.7 | 3.857143 |
| 8 | 3.2 | 5.142857 |
dat_full_anti %>%
head(n = 10) %>%
arrange(id)| id | depression1 | depression2 |
|---|---|---|
| 3 | 3.6 | 5.142857 |
| 7 | 3.7 | 3.857143 |
12.5.3 Why not use full_join() for almost everything?
# shuffle the rows and add duplicates or missingness
set.seed(42)
dat_demographics_many_duplicates <- dat_demographics %>%
# add errors in the form of duplicates
dirt_duplicates(prop = 1)
dat_likert_scored_many_duplicates <- dat_likert_scored %>%
# add errors in the form of duplicates
dirt_duplicates(prop = 1) dat_full_join2 <- full_join(x = dat_demographics_many_duplicates,
y = dat_likert_scored_many_duplicates,
by = "id")
dat_demographics_many_duplicates %>%
count()| n |
|---|
| 16 |
dat_likert_scored_many_duplicates %>%
count()| n |
|---|
| 16 |
dat_full_join2 %>%
count()| n |
|---|
| 32 |
12.6 Exercises 1
Using the existing demographics and Likert data frames:
- How can you keep all rows from the Likert data where there are matching values in demographics data, keeping just columns from Likert data? How many rows are there? Are there duplicates?
- How can you keep all rows from the demographics where there are not matching values in Likert data, keeping just columns from demographics? How many rows are there? Are there duplicates?
- How can you use
full_join()and then a) quantify and b) handle duplicate values?
Hint: we covered a functions to do this in the chapters Data Transformation 1 and Data Transformation 3.
Which columns would you apply these functions to and how? What if your dataset had a lot more columns?
12.7 Exercises 2
Simulated data for a mixed within-between Randomized Controlled Trials examining the effect of an intervention on self-reported social media use. Hypothetically, data was collected before and after intervention, in both an intervention and placebo (waiting list control) group.
Four data sets are created:
- demographics
- scores at pre
- scores at post
- participants to be excluded
set.seed(42)
dat_demographics <-
tibble(id = 1:50) %>%
truffle_demographics() %>%
# randomise row order
sample_frac(size = 1, replace = FALSE) %>%
# add duplicates
dirt_duplicates(prop = .30)
dat_pre <-
truffle_likert(study_design = "factorial_between2",
n_per_condition = 25,
factors = "X1_latent",
prefixes = "socialmediause_item",
alpha = .80,
n_items = 2,
n_levels = 7,
approx_d_between_groups = 0,
seed = 42) %>%
# select just the first social media item,
# to mimic a 1-item measure.
# truffle_likert() has to create at least two items, so this is a workaround.
select(id, condition, socialmediause_pre = socialmediause_item1) %>%
# randomise row order
sample_frac(size = 1, replace = FALSE)
dat_post <-
truffle_likert(study_design = "factorial_between2",
n_per_condition = 25,
factors = "X1_latent",
prefixes = "socialmediause_item",
alpha = .80,
n_items = 2,
n_levels = 7,
approx_d_between_groups = 0.4,
seed = 42) %>%
# select just the first social media item,
# to mimic a 1-item measure.
# truffle_likert() has to create at least two items, so this is a workaround.
select(id, condition, socialmediause_post = socialmediause_item1) %>%
# delete some rows to create missingness
sample_frac(size = .75, replace = FALSE) %>%
# randomise row order
sample_frac(size = 1, replace = FALSE)
dat_exclusions <- tibble(id = c(3, 11, 12))- Join together the four data frames to create a data frame named
data_combined
- Use only
joinfunctions (i.e., not filter or distinct etc.). - Note that you must (sometimes) join by two variables this time, id and condition, to retain both of them without creating two condition variables.
- data_combined should contain all participants that have data at timepoint pre, with missing (NA) data for timepoint post.
- data_combined should also include age and gender data, but without introducing duplicates.
- data_combined should also not include participant IDs that are present in dat_exclusions.
If correctly joined, you could be able to run the next chunk to analyze the RCT data following best practices for RCTs, i.e., an ANCOVA comparing differences at post controlling for differences at pre, estimating the effect size using Morris’ (2008) version of Cohen’s d, d_ppc2 and its 95% Confidence Intervals.
fit <- lm(formula = socialmediause_post ~ socialmediause_pre + condition,
data = dat_combined)
car::Anova(fit, type = 3) |>
report::report()12.8 Exercises 3
set.seed(42)
dat_demographics <-
tibble(id = 1:50) %>%
truffle_demographics() %>%
# randomise row order
sample_frac(size = 1, replace = FALSE) %>%
# add duplicates
dirt_duplicates(prop = .30)
dat_purchases_store_1 <-
tibble(id = 1:50,
purchases_store1 = rnbinom(n = 50, size = 2, mu = 3)) %>%
select(id, purchases_store1) %>%
# delete some rows to create missingness
sample_frac(size = .75, replace = FALSE) %>%
# randomise row order
sample_frac(size = 1, replace = FALSE)
dat_purchases_store_2 <-
tibble(id = 1:50,
purchases_store2 = rnbinom(n = 50, size = 2, mu = 1.5)) %>%
select(id, purchases_store2) %>%
# delete some rows to create missingness
sample_frac(size = .60, replace = FALSE) %>%
# randomise row order
sample_frac(size = 1, replace = FALSE)
dat_purchases_store_3 <-
tibble(id = 1:50,
purchases_store3 = rnbinom(n = 50, size = 2.1, mu = 1.75)) %>%
select(id, purchases_store3) %>%
# delete some rows to create missingness
sample_frac(size = .40, replace = FALSE) %>%
# randomise row order
sample_frac(size = 1, replace = FALSE)