dat <- read_csv("data_shouldnt_usually_go_here.csv")4 Loading, viewing and saving data
4.1 Using .csv files rather than Excel .xlsx files
While Microsoft Excel’s .xlsx files provide many features, in the context of reproducible data processing and analysis they often introduce more risks than benefits.
Excel allows the user to write formula to process and analyze data. However, Excel formula are less reproducible than R code as they are not always visible to the user and it is easy to make copy paste and cell location errors.
This isn’t merely speculation:
4.1.1 Case study 1: Reinhard & Rogoff (2010)
In the immediate aftermath of the 2008 Financial Crisis, an article by then-Harvard Professor and previously Chief Economist of the International Monetary Fund, Kenneth Rogoff, was heavily referenced by economists as part of the rationale to dramatically cut state spending (Reinhart & Rogoff (2010)). Countries including my own, Ireland, the U.K. and others adopted radical austerity policies and slashed funding to education and healthcare, from which we have not yet fully recovered from. Thomas Herndon, then a first year PhD student, found serious errors in Reinhart and Rogoff’s Excel formula (Herndon et al. (2014)). When corrected, the results indicated that austerity policies were harmful rather than helpful. Global economic history was changed by this data processing error.
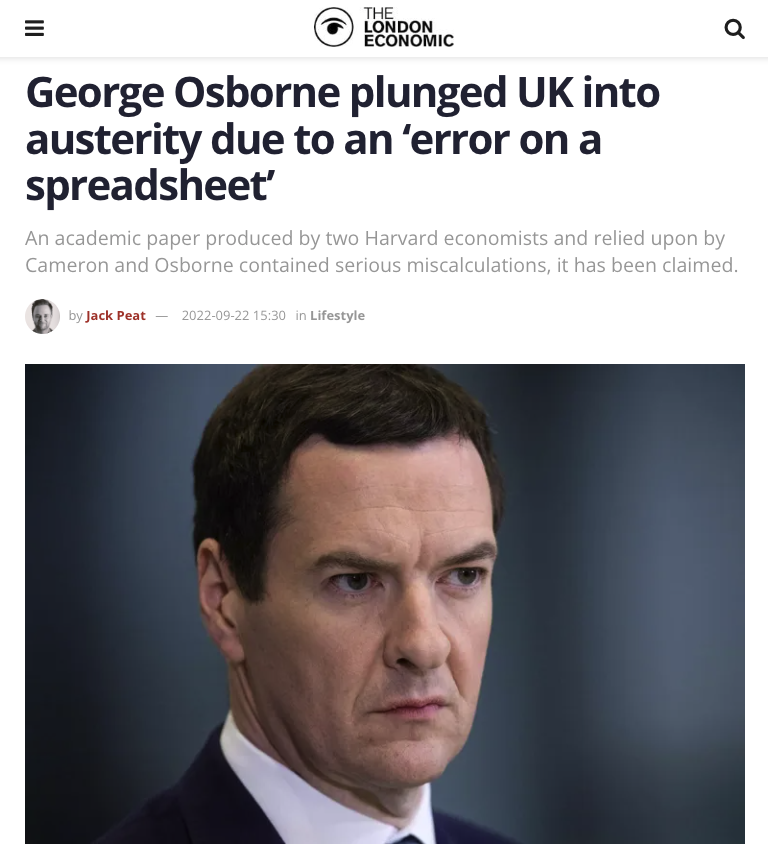
For coverage of this fascinating and horrifying story:
4.1.2 Case study 2: Excel corrupts the genomics literature
Excel’s automatic data conversion ‘feature’ turns certain text strings that also happen to refer to identifiers for genes (e.g., SEPT2, MARCH1) into dates or numbers. When genetics data is opened in Excel, automatically converted, and then saved, these silent changes propagated into data analyses. Ziemann et al. (2016) estimated that ~20% of papers with Excel gene lists contained such errors, demonstrating field-wide contamination of results and reproducibility risks (see coverage in Science News). Subsequent audits showed the problem persisted years later, despite awareness of the problem and guidance on how to prevent it, underscoring how Excel can corrupt bioinformatics workflows (see Abeysooriya et al., 2021).
4.1.3 Other reasons to avoid Excel
Other less extreme but nonetheless good reasons not to use Excel and .xlsx files also exist. Use colors (in cells or text) to carry information (e.g., “cells in red represent the outcome variables”), which can’t be easily read into R. Generally, colorful .xlsx files are a statistician’s nightmare.
So, we’ll use .csv files and avoid manually altering data outside of reproducible R workflows.
4.2 Loading .csv files
4.2.1 read.csv() and readr::read_csv()
Base R’s read.csv() has a slightly better version in the {readr} package, readr::read_csv(), which is more explicit about how it parses column types. This can become useful in more complex data sets. I recommend you use read_csv() and will use it throughout this book.
4.2.2 Relative vs. absolute paths: Avoid using setwd()!
Where to load data from?
When we write .R scripts, we often use setwd() to define where files should be loaded from and saved to. The problem with setwd() is that it hard-codes file paths that are usually specific to the computer and user. For example, if I write an .R script that includes setwd("C:/Users/IanHussey/Documents/R_course/"), before loading some data using read_csv(). If I email you this script and data file, it script won’t work on your machine unless your folders are identically named; you have to change the file path in setwd(). This lowers the reproducibility of the code, as it can’t be run trivially by other people on other computers.
This is because setwd() uses ‘absolute’ paths that point to a specific location in a directory structure. One of the very useful features of RMarkdown (.Rmd) and Quarto (.qmd) files is that they instead use ‘relative’ paths, which specify where a file or directory is in relation to the .Rmd or .qmd script. That is, the working directory is by definition wherever the .Rmd or .qmd file is, without being specified.
If I have a directory - located anywhere on my hard drive - called ‘R_course’ that contains the folders ‘code’ and ‘data’, and the ‘data’ directory itself contains the directories ‘processed’ and ‘raw’. Imagine the files within these directories are as follows:
R_course/
├── code/
│ ├── analysis.qmd
│ ├── data_shouldnt_usually_go_here.csv
│ └── processing.qmd
└── data/
├── processed/
│ ├── data_processed.csv
│ └── ... (other .csv files)
└── raw/
├── data_likert.csv
├── code_shouldnt_usually_go_here.qmd
└── ... (other .csv files)Because .qmd files use ‘relative’ paths, to load the ‘data_shouldnt_usually_go_here.csv’ file I only need to do the following, without any setwd() call:
Of course, code and data should be clearly separated within a project so ‘data_shouldnt_usually_go_here.csv’ should not usually go in that directory, as the name suggests.
If I instead wanted to load ‘data_likert.csv’, I would do this as follows. This data file actually exists in this project, so the code will run assuming you have the data files in the correct location relative to this .qmd script.
library(readr)
dat_likert <- read_csv("../data/raw/data_likert.csv")This is parsed as follows: ../ tells RStudio to go ‘up’ one directory level from ‘analysis.qmd’ to the ‘R_course’ folder that contains it. data/ then tells it to go ‘down’ one level into the ‘data’ folder inside ‘R_course’. Likewise, processed/ then tells it to go ‘down’ another level into the ‘processed’ folder, before loading the ‘data_likert.csv’ file.
Note that ../ can be stacked to go ‘up’ multiple directory levels, e.g., ../../.
As long as you send move the entire ‘R_course’ folder and preserve the relative location between the code and the data, the .qmd file’s read_csv() call will still work. It doesn’t matter whether you the ‘R_course’ directory to somewhere else on your hard drive, or create a .zip file and email it to someone else, or distribute it via GitHub, or whether they’re using Windows or Mac.
Also note that because the directory ‘R_course’ is never specified in the read_csv() call, it can be called anything else and still work. The same goes for the name of the script which calls read_csv() - in this case, the script you’re reading is called ‘loading_data.qmd’ and the code still works.
FYI, you can also use relative paths in regular .R files using the {here} library.
4.2.3 Understanding directory structures with list.files(), list.dirs(), file.exists() and dir.exists()
When trying to write relative paths to load or save data, it often takes me a few attempts to get it right. I go back and forth looking at the files and directories themselves in File Explorer (Widows) or Finder (Mac) and adjusting the R code.
You can also explore directory and file structures directly in R to make this easier using list.files() to list files and list.dirs() to list directories.
List the files in the same folder as this .qmd file:
list.files() [1] "1_setup.html" "1_setup.qmd"
[3] "10_strings_and_factors.qmd" "11_reshaping_and_pivots.qmd"
[5] "12_binding_and_joining.qmd" "13_sharing_and_privacy.qmd"
[7] "14_visualization.qmd" "15_reporting.qmd"
[9] "16_the_linear_model.qmd" "2_fundamentals_files"
[11] "2_fundamentals.html" "2_fundamentals.qmd"
[13] "3_reproducible_reports_files" "3_reproducible_reports.html"
[15] "3_reproducible_reports.qmd" "4_loading_data.qmd"
[17] "4_loading_data.rmarkdown" "5_the_pipe_and_renaming.qmd"
[19] "6_data_transformation_1.qmd" "7_data_transformation_2.qmd"
[21] "8_data_transformation_3.qmd" "9_structuring_projects.qmd"
[23] "images" "plots"
[25] "project_1.qmd" "project_2.qmd"
[27] "sum_score.qmd" "updating.qmd" Go ‘up’ one directory and list the directories present:
list.dirs(path = "../", # 'up' one directory level
full.names = FALSE, # abbreviated dir names
recursive = FALSE) # only the directories, not their contents [1] "_book" ".git" ".quarto" ".Rproj.user"
[5] "answers" "chapters" "data" "exercises"
[9] "images" "old" "project_template" "R"
[13] "resources" "site_libs" "slides" "videos" From the above we can see that the ‘data’ folder is up one directory level from the current .qmd file. Let’s confirm this with dir.exists() to check the directory does indeed exist:
dir.exists("../data")[1] TRUEOk, we’re getting close. So what’s in the ‘../data’ directory?
list.dirs(path = "../data", # 'up' one directory level, then 'down' into 'data'
full.names = FALSE, # abbreviated dir names
recursive = FALSE) # only the directories, not their contents[1] "processed" "raw" It contains the folders ‘processed’ and ‘raw’. What’s in the ‘raw’ directory?
list.files("../data/raw") [1] "data_age_gender_subset.csv" "data_amp_raw.csv"
[3] "data_amp_summary_subset.csv" "data_demographics_raw_messy.csv"
[5] "data_demographics_raw.csv" "data_likert_messy.csv"
[7] "data_likert.csv" "data_likert.rds"
[9] "data_likert.xlsx" "data_raw_bfi.csv"
[11] "data_selfreport_raw.csv" "data_selfreport_summary_subset.csv"
[13] "data_unique_id_subset.csv" If we were looking to find and load the ‘data_likert.csv’ file, we know its directory path and that it exists. As already used above:
dat_likert <- read_csv("../data/raw/data_likert.csv")4.2.4 Creating new directories with dir.create()
Sometimes, you might want to save files to a directory does not yet exist.
On the one hand, you could just open File Explorer (Windows) or Finder (Mac) and create a new directory manually (e.g., File>New folder).
However, we want our R code to be highly reproducible. Requiring manual steps like the above often breaks the code on other people’s machines.
Instead, you can create folders directly from R using dir.create(). For example, if your analysis script is located at R_course/code/analysis.qmd, and you want to save plots that you create to a ‘plots’ directory within ‘code’, you can include this line in your ‘analysis.qmd’ file:
dir.create("plots")4.2.5 Other file and directory functions
You can also rename, copy, delete, and move files and directories with functions such as file.rename(), file.copy(), file.remove(), file.move(). Use the help menu to discover and understand these and other functions.
4.3 Viewing data frames
4.3.1 In your environment
Data frames (and other objects) that have already been loaded into your R environment will appear under the ‘files’ tab in RStudio.
You can view them by clicking on them in the ‘Environment’ tab in RStudio, running View(object) (where ‘object’ is your object’s name, e.g. View(dat_likert)), or clicking the object’s name in the Source window where code appears with Cmd+click (on Mac) or Ctrl+click (on Windows).
4.3.2 Printing data frames below chunks
To print a data frame below the code chunk, you can;
Run the object name:
dat_likert| …1 | …2 | …3 | …4 | …5 | …6 | …7 | …8 | …9 | …10 | …11 | …12 | …13 | …14 | …15 | …16 | …17 | …18 | …19 | …20 | …21 | …22 | …23 | …24 | …25 | …26 | …27 | …28 | …29 | …30 | …31 | date | group | subject | likert_1 | likert_2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 23.06.2022 | 1 | 1 | 1 | 4 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 23.06.2022 | 2 | 2 | 3 | 3 |
| 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 23.06.2022 | 2 | 3 | 2 | 1 |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 23.06.2022 | 1 | 4 | 5 | 5 |
| 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 23.06.2022 | 1 | 5 | 3 | 3 |
| 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 23.06.2022 | 2 | 6 | 2 | 1 |
| 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 23.06.2022 | 1 | 7 | 2 | 1 |
| 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 23.06.2022 | 1 | 8 | 1 | 3 |
| 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 23.06.2022 | 1 | 9 | 2 | 5 |
| 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 23.06.2022 | 2 | 10 | 5 | 2 |
| 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 23.06.2022 | 1 | 11 | 1 | NA |
| 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 23.06.2022 | 2 | 12 | 3 | NA |
| 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 23.06.2022 | 2 | 13 | 2 | NA |
| 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 23.06.2022 | 1 | 14 | 5 | NA |
| 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 23.06.2022 | 1 | 15 | 3 | NA |
| 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 23.06.2022 | 2 | 16 | 2 | NA |
| 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 23.06.2022 | 1 | 17 | 2 | NA |
| 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 23.06.2022 | 1 | 18 | 1 | NA |
| 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 23.06.2022 | 1 | 19 | 2 | NA |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 23.06.2022 | 2 | 20 | 5 | NA |
Use print():
print(dat_likert)# A tibble: 20 × 36
...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8 ...9 ...10 ...11 ...12 ...13
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 1 1 1 1 1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3 3 3 3 3 3 3
4 4 4 4 4 4 4 4 4 4 4 4 4 4
5 5 5 5 5 5 5 5 5 5 5 5 5 5
6 6 6 6 6 6 6 6 6 6 6 6 6 6
7 7 7 7 7 7 7 7 7 7 7 7 7 7
8 8 8 8 8 8 8 8 8 8 8 8 8 8
9 9 9 9 9 9 9 9 9 9 9 9 9 9
10 10 10 10 10 10 10 10 10 10 10 10 10 10
11 11 11 11 11 11 11 11 11 11 11 11 11 11
12 12 12 12 12 12 12 12 12 12 12 12 12 12
13 13 13 13 13 13 13 13 13 13 13 13 13 13
14 14 14 14 14 14 14 14 14 14 14 14 14 14
15 15 15 15 15 15 15 15 15 15 15 15 15 15
16 16 16 16 16 16 16 16 16 16 16 16 16 16
17 17 17 17 17 17 17 17 17 17 17 17 17 17
18 18 18 18 18 18 18 18 18 18 18 18 18 18
19 19 19 19 19 19 19 19 19 19 19 19 19 19
20 20 20 20 20 20 20 20 20 20 20 20 20 20
# ℹ 23 more variables: ...14 <dbl>, ...15 <dbl>, ...16 <dbl>, ...17 <dbl>,
# ...18 <dbl>, ...19 <dbl>, ...20 <dbl>, ...21 <dbl>, ...22 <dbl>,
# ...23 <dbl>, ...24 <dbl>, ...25 <dbl>, ...26 <dbl>, ...27 <dbl>,
# ...28 <dbl>, ...29 <dbl>, ...30 <dbl>, ...31 <dbl>, date <chr>,
# group <dbl>, subject <dbl>, likert_1 <dbl>, likert_2 <dbl>4.3.3 Printing nicer tables
Printing data frames by calling their name or using print() don’t produce very attractive tables. You can improve this using a combination of the {knitr} and {kableExtra} packages.
Note that this code uses the ‘pipe’ (%>%), which we cover in more detail in a later chapter. You don’t need to understand how it works yet, just the output that it creates.
library(knitr)
library(kableExtra)
dat_likert %>%
knitr::kable(align = "r") %>%
kableExtra::kable_styling(full_width = FALSE)| ...1 | ...2 | ...3 | ...4 | ...5 | ...6 | ...7 | ...8 | ...9 | ...10 | ...11 | ...12 | ...13 | ...14 | ...15 | ...16 | ...17 | ...18 | ...19 | ...20 | ...21 | ...22 | ...23 | ...24 | ...25 | ...26 | ...27 | ...28 | ...29 | ...30 | ...31 | date | group | subject | likert_1 | likert_2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 23.06.2022 | 1 | 1 | 1 | 4 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 23.06.2022 | 2 | 2 | 3 | 3 |
| 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 23.06.2022 | 2 | 3 | 2 | 1 |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 23.06.2022 | 1 | 4 | 5 | 5 |
| 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 23.06.2022 | 1 | 5 | 3 | 3 |
| 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 23.06.2022 | 2 | 6 | 2 | 1 |
| 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 23.06.2022 | 1 | 7 | 2 | 1 |
| 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 23.06.2022 | 1 | 8 | 1 | 3 |
| 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 23.06.2022 | 1 | 9 | 2 | 5 |
| 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 23.06.2022 | 2 | 10 | 5 | 2 |
| 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 23.06.2022 | 1 | 11 | 1 | NA |
| 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 23.06.2022 | 2 | 12 | 3 | NA |
| 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 23.06.2022 | 2 | 13 | 2 | NA |
| 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 23.06.2022 | 1 | 14 | 5 | NA |
| 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 23.06.2022 | 1 | 15 | 3 | NA |
| 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 23.06.2022 | 2 | 16 | 2 | NA |
| 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 23.06.2022 | 1 | 17 | 2 | NA |
| 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 23.06.2022 | 1 | 18 | 1 | NA |
| 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 23.06.2022 | 1 | 19 | 2 | NA |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 23.06.2022 | 2 | 20 | 5 | NA |
4.4 Saving .csv files
Writing .csv files to disk is as easy as loading them.
write.csv(x = dat_likert, # the data frame to save
file = "../data/raw/data_likert.csv") # the file to save it to4.5 Loading .xlsx files
While .csv files are a good default file format to use for most projects, Excel, SPSS, and other file formats can also be loaded.
There are several packages available to load Excel files in particular. Any of them are fine except library(xlsx) which requires you to install rJava, which often causes compatibility issues. library(readxl) is a safer bet. Because excel files can contain multiple sheets, the source can be specified with the sheet argument.
library(readxl)
dat_likert_1 <- readxl::read_excel(path = "../data/raw/data_likert.xlsx",
sheet = "data1")4.5.1 Skipping rows when loading
Sometimes extra rows etc. make a data file harder to read into R. For example, the column names in ‘data_likert.xlsx’ are on the fourth row, causing a mess when you load the file.
You can view column names, types and the first few rows of data with head():
head(dat_likert_1)| Date created: 02/04/2024 | …2 | …3 | …4 | …5 |
|---|---|---|---|---|
| subset: sample 1 | NA | NA | NA | NA |
| NA | NA | NA | NA | NA |
| date | group | subject | likert_1 | likert_2 |
| 44735 | 1 | 1 | 1 | 4 |
| 44735 | 2 | 2 | 3 | 3 |
| 44735 | 2 | 3 | 2 | 1 |
With a few exceptions (e.g., removing identifying information before making data public), you should not manually modify raw data.
It might be tempting to open the .csv file in excel and manually delete those rows - don’t!
Handle with code, not by deleting the information in those rows. When using read_csv() or readxl::read_excel() this can be done using the skip argument.
dat_likert_1 <- readxl::read_excel(path = "../data/raw/data_likert.xlsx",
sheet = "data1",
skip = 3)
dat_likert_1| date | group | subject | likert_1 | likert_2 |
|---|---|---|---|---|
| 2022-06-23 | 1 | 1 | 1 | 4 |
| 2022-06-23 | 2 | 2 | 3 | 3 |
| 2022-06-23 | 2 | 3 | 2 | 1 |
| 2022-06-23 | 1 | 4 | 5 | 5 |
| 2022-06-23 | 1 | 5 | 3 | 3 |
4.6 Combining multiple data sets
You can combine multiple data sets with (nearly) the same structure using dplyr::bind_rows(). In this case, ‘data_likert.xlsx’ have mostly the same columns, with sheet 1 also having the ‘likert_2’ column. Missing columns are filled with NA when using dplyr::bind_rows(). This has its advantages over base R’s rbind() which requires that column names must match between the objects.
library(dplyr)
dat_likert_1 <- readxl::read_excel("../data/raw/data_likert.xlsx", sheet = "data1", skip = 3)
dat_likert_2 <- readxl::read_excel("../data/raw/data_likert.xlsx", sheet = "data2", skip = 3)
dat_likert <- dplyr::bind_rows(dat_likert_1,
dat_likert_2)
dat_likert| date | group | subject | likert_1 | likert_2 |
|---|---|---|---|---|
| 2022-06-23 | 1 | 1 | 1 | 4 |
| 2022-06-23 | 2 | 2 | 3 | 3 |
| 2022-06-23 | 2 | 3 | 2 | 1 |
| 2022-06-23 | 1 | 4 | 5 | 5 |
| 2022-06-23 | 1 | 5 | 3 | 3 |
| 2022-06-23 | 1 | 6 | 1 | NA |
| 2022-06-23 | 2 | 7 | 3 | NA |
| 2022-06-23 | 2 | 8 | 2 | NA |
| 2022-06-23 | 1 | 9 | 5 | NA |
| 2022-06-23 | 1 | 10 | 3 | NA |
4.7 Loading and writing .rda files
R objects can also be saved and loaded as .rda files. This can be very useful if you want to a) compress the data to make it smaller (using the compress = "gz" argument) or b) to preserve things like column types and factor levels. However, it does slightly reduce the interoperability of the data as not everyone else uses R.
library(readr)
# write
readr::write_rds(x = dat_likert,
file = "../data/raw/data_likert.rds",
compress = "gz")
# read
dat_likert <- readr::read_rds(file = "../data/raw/data_likert.rds")4.8 Loading multiple data files at once
Some psychology software such as PsychoPy often saves each participant’s data as a separate .csv file. FYI you can write code to find all files of a given type (e.g., .csv) in a folder, read them all in, and bind all the data together as a single data frame. Note that this code uses some functions from the {purrr} package not explained here. It’s included here so that you know that it can be done quite easily.
library(purrr)
# list all the files in a directory
file_names <- list.files(path = "../data/raw/individual_files",
pattern = "\\.csv$",
full.names = TRUE)
# use (or 'map') the read_csv function onto each of the file names
data_combined <- purrr::map_dfr(.x = file_names, .f = read_csv)4.9 Exercises
Check your learning with the following questions. Exercises involving running code should be run in your local copy of the .qmd files (see the Introduction to get a copy of them).
4.9.1 How can you run all the code chunks in this file with a single click?
NoteClick to show answer
Clicking the green down arrow button in the last chunk.
See the chapter on Reproducible Reports to refresh your knowledge.
Do this in order to load all the objects into your environment so that you can complete the next exercise.
4.9.2 What are three ways to view the contents of an object?
Do all three ways for the dat_likert object.
NoteClick to show answer
- Clicking the object’s name the ‘Environment’ tab in RStudio
- Running
View(object)(where ‘object’ is your object’s name) - Clicking the object’s name in the Source window (where code appears) with Cmd+click (on Mac) or Ctrl+click (on Windows)
4.9.3 How would you know what arguments read_excel() takes?
NoteClick to show answer
By consulting the help menu with by running ?read_excel() either directly in the console or in a code file.
Note that you have to either first load the {read_xl} package with library(readxl), or specify which package the function comes from with ?readxl::read_excel(). See the section on dependencies in the chapter on Fundamentals to refresh your knowledge.
4.9.4 How to use relative paths to load files?
Using the file structure diagram under the Relative vs. absolute paths section above, what R code is needed to load the ‘data_shouldnt_usually_go_here.csv’ file from the ‘code_shouldnt_usually_go_here.qmd’?
NoteClick to show hint
You need to understand relative paths and use “../” to go ‘up’ directories.
NoteClick to show answer
dat <- read_csv("../../code/data_shouldnt_usually_go_here.csv")4.9.5 Load and print nicely formatted table
Following the same file structure as above, there is a file called “data_likert.csv” in the ‘raw’ data directory.
Write R code to:
- Load that data file from this .qmd file, which is located in the ‘code’ directory.
- Assign it to an object called
dat_likert. - Load the {knitr} and {kableExtra} libraries.
- Print
dat_likertas nicely formatted table.
# include: false
NoteClick to show hint
See the chapter on Fundamentals to refresh your knowledge on loading dependencies/libraries and object assignment.
Adapt the code used in this chapter for the other steps.
NoteClick to show answer
dat_likert <- read_csv("../data/raw/data_likert.csv")
library(knitr)
library(kableExtra)
dat_likert %>%
kable(align = "r") %>%
kable_styling(full_width = FALSE)| ...1 | ...2 | ...3 | ...4 | ...5 | ...6 | ...7 | ...8 | ...9 | ...10 | ...11 | ...12 | ...13 | ...14 | ...15 | ...16 | ...17 | ...18 | ...19 | ...20 | ...21 | ...22 | ...23 | ...24 | ...25 | ...26 | ...27 | ...28 | ...29 | ...30 | ...31 | ...32 | date | group | subject | likert_1 | likert_2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 23.06.2022 | 1 | 1 | 1 | 4 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 23.06.2022 | 2 | 2 | 3 | 3 |
| 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 23.06.2022 | 2 | 3 | 2 | 1 |
| 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 23.06.2022 | 1 | 4 | 5 | 5 |
| 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 23.06.2022 | 1 | 5 | 3 | 3 |
| 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 23.06.2022 | 2 | 6 | 2 | 1 |
| 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 23.06.2022 | 1 | 7 | 2 | 1 |
| 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 23.06.2022 | 1 | 8 | 1 | 3 |
| 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 23.06.2022 | 1 | 9 | 2 | 5 |
| 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 10 | 23.06.2022 | 2 | 10 | 5 | 2 |
| 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 23.06.2022 | 1 | 11 | 1 | NA |
| 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 23.06.2022 | 2 | 12 | 3 | NA |
| 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 13 | 23.06.2022 | 2 | 13 | 2 | NA |
| 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 23.06.2022 | 1 | 14 | 5 | NA |
| 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 23.06.2022 | 1 | 15 | 3 | NA |
| 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 23.06.2022 | 2 | 16 | 2 | NA |
| 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 17 | 23.06.2022 | 1 | 17 | 2 | NA |
| 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 23.06.2022 | 1 | 18 | 1 | NA |
| 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 19 | 23.06.2022 | 1 | 19 | 2 | NA |
| 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 23.06.2022 | 2 | 20 | 5 | NA |
4.9.6 Check whether ‘data_likert.rds’ exists
Earlier steps in this lesson saved a file called ‘data_likert.rds’ to the same directory as ‘data_likert.csv’.
Use the functions list.dirs(), list.files(), and file.exists() to navigate the file structure, listing directories along the way, to write the file.exists() call that confirm that the file exists. It should return TRUE.
NoteClick to show answer
list.dirs(path = "../", # 'up' one directory level
full.names = FALSE, # abbreviated dir names
recursive = FALSE) # only the directories, not their contents [1] "_book" ".git" ".quarto" ".Rproj.user"
[5] "answers" "chapters" "data" "exercises"
[9] "images" "old" "project_template" "R"
[13] "resources" "site_libs" "slides" "videos" list.dirs(path = "../data", # 'up' one directory level, down one into 'data'
full.names = FALSE, # abbreviated dir names
recursive = FALSE) # only the directories, not their contents[1] "processed" "raw" list.files(path = "../data/raw", # 'up' one directory level, down one into 'data', down another into 'raw'
full.names = FALSE, # abbreviated dir names
pattern = "\\.rds$", # only return files ending in ".rds"
recursive = FALSE) # only the directories, not their contents[1] "data_likert.rds"file.exists("../data/raw/data_likert.rds")[1] TRUE